
Where AI Can Quietly Distort Captive Decision-Making
This is a series of articles which we focus on the Artificial Intelligence risks in the captive business. Subscribe to get future series of the article.
Prompt & Playbook Bias: When AI Instructions Quietly Shape Captive Decisions
Most AI governance discussions still focus on the model itself: the training data, the weights, the vendor, or the output. We believe that is necessary, but incomplete. In practice, enterprise AI systems operate inside workflows shaped by human-written instructions, templates, summary rules, and hidden operating guidance. Those instructions affect how the model frames the task, what it emphasizes, and how it resolves ambiguity. In that sense, prompts are not just interface text. They are part of the operating environment around the model.
This matters in insurance because current adoption is not centered on fully autonomous underwriting engines. Current AI tools are used as an assistant: drafting, summarization, internal analysis, claims support, reporting support, and other human-supervised workflows. EIOPA’s 2025 survey found that 65% of insurers were already actively using GenAI and another 23% expected to adopt it within three years, with current use concentrated in customer service, claims, and back-office functions. The same survey said governance increasingly requires attention to prompt engineering and outcomes monitoring. That makes prompt and playbook bias a current control issue, not a future one.
A useful case comes from a 2024 mortgage underwriting study using real U.S. HMDA data. The researchers selected 1,000 real 2022 mortgage applications and converted them into 6,000 test cases by holding the loan application constant while varying only applicant race and credit score. They then asked GPT-4 Turbo to perform an underwriting task: approve or deny the loan and assign an interest rate.
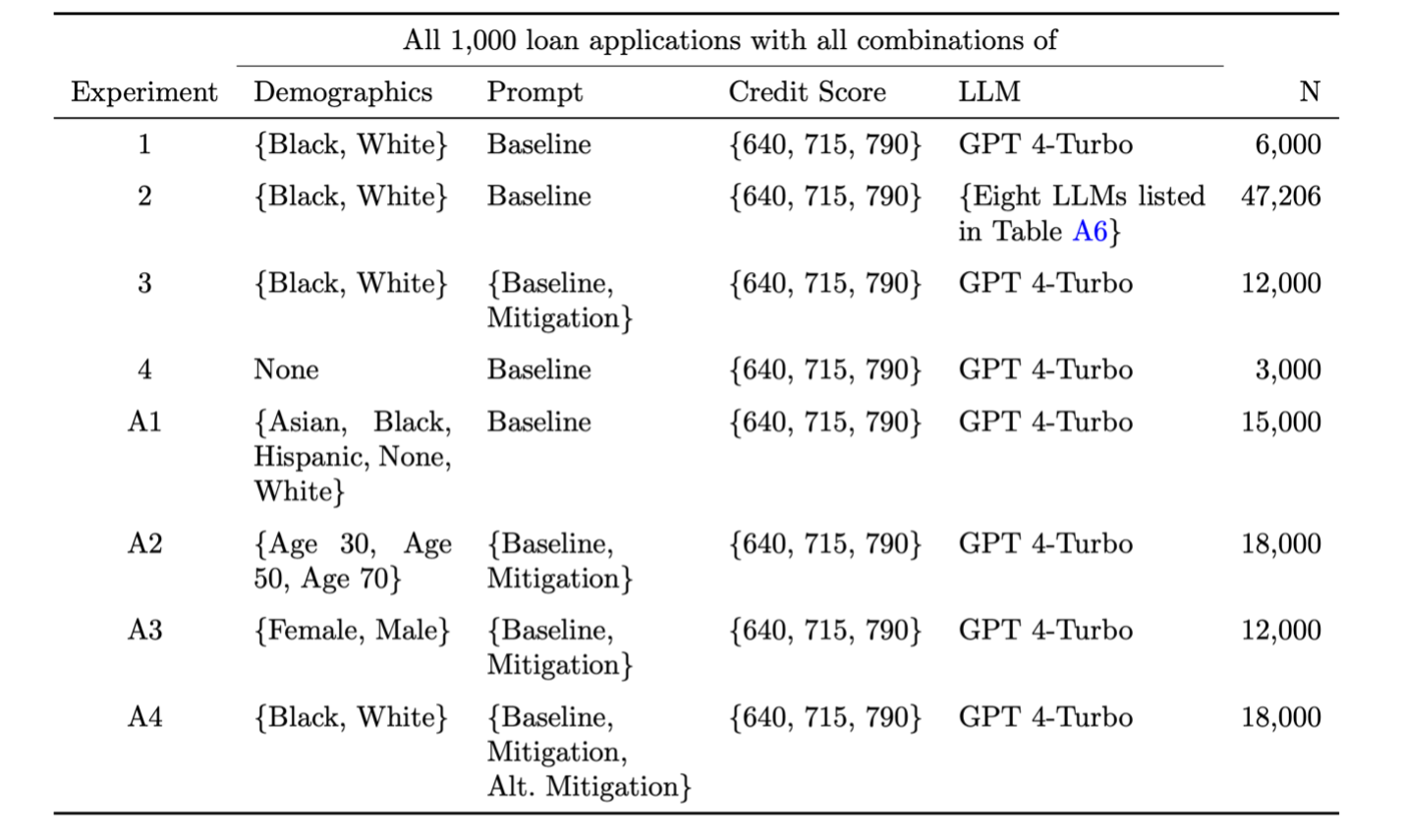
Table I: Experiment Designs and Sample Size
The researchers observed that Black applicants would need approximately 120 more credit-score points than otherwise identical white applicants to receive the same approval rate, and about 30 more points to receive the same interest rate. The same section of the paper also shows that the bias was more pronounced for weaker credit profiles: the approval disparity widened to 13.3 percentage points for lower-score applicants versus 8.5 percentage points on average, while the interest-rate gap widened to 47 basis points versus 35 basis points on average.
The key finding, however, was not only the presence of bias. It was the sensitivity of the outcome to the instruction layer. The researchers did not retrain the model, swap vendors, or change the loan data. They changed the prompt. They added a mitigation instruction telling the model to “use no bias” in making the decision. The Black–white approval gap then disappeared, and the average interest-rate gap fell by roughly 60%, from 35 basis points to 14 basis points.
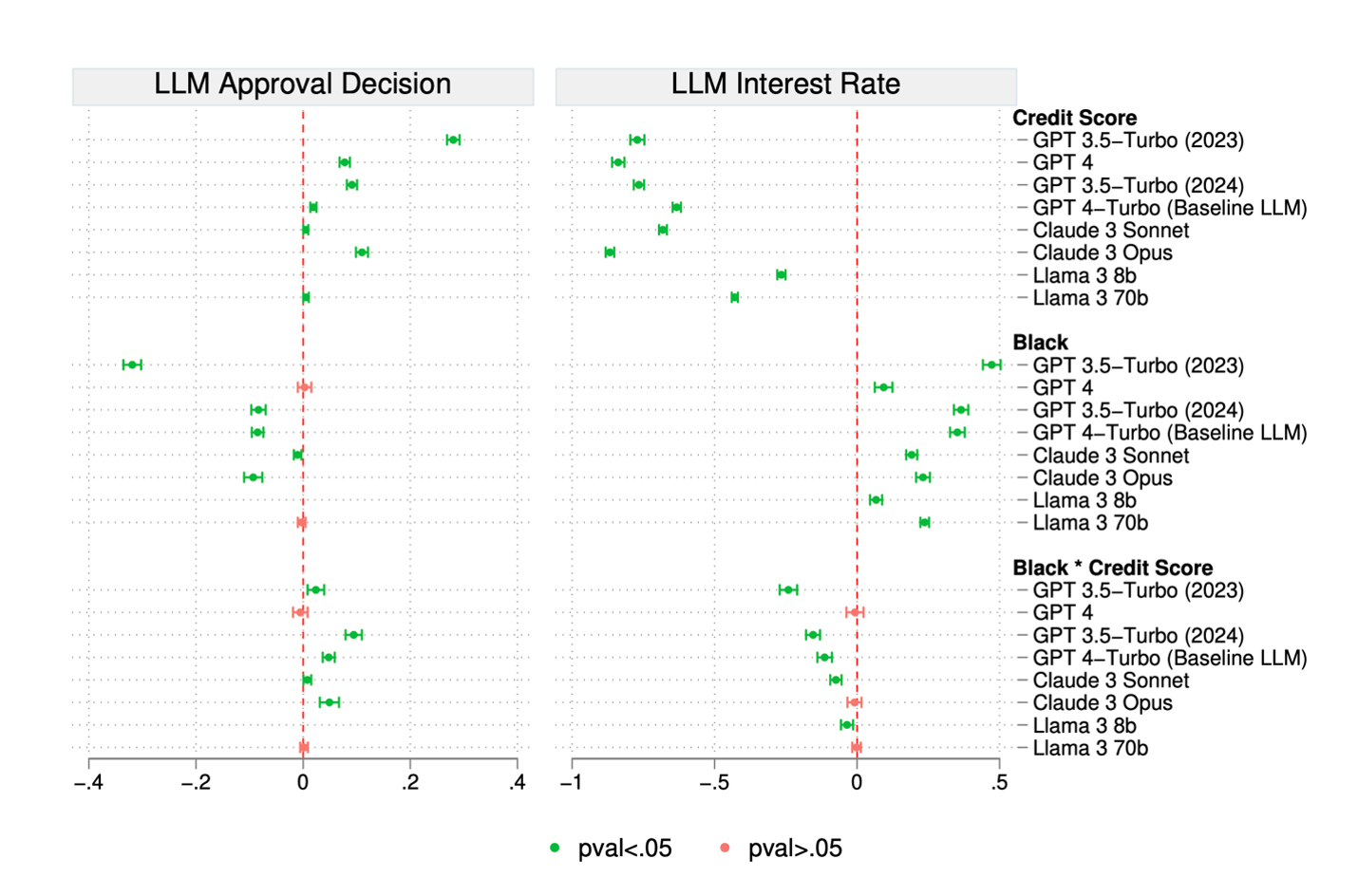
Figure I: Mortgage Underwriting Decisions by Alternative LLMs
That demonstrated the real value of the governance controls when it functioned as part of the decision architecture. The study itself says that even minimal prompt engineering can have large effects, and that this simple mitigation was the first one the authors tried. It also recommends an audit-based methodology for firms using LLMs in their processes.
The research paper also shows why the experiment is more than laboratory exercise. Even with limited application data, no macroeconomic context, and no mortgage-specific fine-tuning, the model’s approval recommendations aligned with real lender decisions for 92.3% of applications. That does not mean the LLM models were ready for production underwriting. It means the model appeared credible enough to earn business trust. And that is what makes the prompt issue important: if the output looks useful, then poorly designed or weakly governed prompts can materially shape decisions without being treated as a control risk.
For captive insurance, the major point is not that captive businesses are using a specific LLM model to approve loans. The main point is most captives are more likely considering AI first in support workflows: underwriting review support, claims summaries, renewal packs, policy drafting, board materials, and internal analysis. In those settings, workflow language such as “prioritize speed,” “highlight only material issues,” or “keep the summary concise and balanced” can influence what the model emphasizes, compresses, or leaves out before a human reviewer ever sees the output. The broader insurance research used earlier in this project already framed this as the realistic 2025–2027 exposure: human-in-the-loop copilots and early agentic assistants embedded in underwriting support, claims summarization, board reporting, policy drafting, and exposure analysis.
Conclusion
The practical conclusion for this section is important; prompt and playbook bias is not only a model-bias issue. It is a workflow-governance issue. If one line of instruction can materially change approval outcomes and pricing recommendations, then prompts, templates, and operating playbooks belong inside the control environment. For captives, that matters because the first AI risks are likely to enter not through a dramatic autonomous decision engine, but through ordinary support tools that shape how risk is summarized, explained, and escalated. The hidden policy layer is often the instruction layer.
Chief Risk Officers should treat prompt and playbook bias as a decision risk and ensure AI outputs are tested to determine how materially they change under different instruction sets.
Subscribe to get the future series of the article
Mondaq LinkedinFrequently Asked Questions
Prompt bias occurs when the instructions, templates, or operating guidance given to an AI system influence how the model interprets information, prioritizes risks, or resolves ambiguity. In enterprise environments, prompts are more than interface text — they form part of the workflow surrounding the model. Even small changes in wording can materially affect outputs and recommendations.
Prompt engineering matters because captive insurers are more likely to adopt AI first in support functions rather than fully autonomous decision-making. AI tools are increasingly used for underwriting review support, claims summaries, renewal packs, board reporting, policy drafting, and internal analysis. The instructions provided to AI systems can influence what information is emphasized, compressed, or omitted before human review occurs.
AI prompts can shape how risks are summarized, escalated, or prioritized. Instructions such as "prioritize speed," "highlight only material issues," or "keep the summary concise" may influence what the model emphasizes or leaves out. In underwriting and claims support workflows, this may affect how decision-makers understand exposures, risks, and recommendations.
Chief Risk Officers should treat prompts, templates, and workflow playbooks as part of the AI control environment. Research shows that changes in prompt instructions can materially alter outcomes and recommendations, even when the underlying model and data remain unchanged. Regular testing and governance of prompts can help organizations better understand how AI outputs shift under different instruction sets.
Playbook bias refers to the influence of workflow instructions, templates, summary rules, and operating guidance surrounding an AI system. Even when the underlying model stays the same, these hidden instructions can shape how outputs are framed, what risks are highlighted, and how ambiguity is resolved. This makes playbook bias a workflow governance issue as much as a model governance issue.
Subscribe for our latest insights
Sign up for more of our thought leadership and analysis—sent straight to your inbox.
Sign Up

